This post is the version of the explainer I wish I had three years ago. Each piece of math gets one figure, one code block, and one paragraph of why-it-is-the-way-it-is. By the end you should understand why a phase- field solver looks the way it does, what’s hard about turning one into a PyTorch module, and why differentiability changes what you can do with one.
The annotated walk-through format is borrowed from Sasha Rush’s Annotated Transformer; if you’ve never read it, go read it first — it’s the template.
1. The thing we are modelling
A crack is a discontinuity in a continuum. That is the whole problem.
Classical fracture mechanics — Griffith, 1921 — frames crack growth as an energy bookkeeping exercise: a crack advances when the elastic strain energy released by its growth equals or exceeds the energy required to create new surface. The bookkeeping is exact, but it requires you to track a moving discontinuity. Numerically, that’s horrible. You need remeshing, level sets, branch detection, criteria for nucleation versus propagation, special elements at the tip — every one of which is its own decade of research.
Phase-field methods sidestep the whole apparatus by replacing the
discontinuity with a smooth scalar damage field d(x, t) ∈ [0, 1].
0 is intact material; 1 is fully cracked. Wherever d is high, the
material has effectively dissolved — its stiffness is multiplied by a
degradation function g(d) = (1 - d)².

The regularisation length ℓ controls how diffuse the crack is. Smaller ℓ → sharper representation → finer mesh required. There is a Γ-convergence result (Ambrosio-Tortorelli, 1990; lifted to fracture by Bourdin, Francfort and Marigo, 2000) that says the phase-field functional converges as a variational problem to Griffith’s surface-energy functional as ℓ → 0. That theorem is the reason this whole field exists.
2. The energy functional, annotated
The variational form is
\[\mathcal{E}(u, d) = \underbrace{\int_\Omega g(d)\,\psi(\varepsilon(u))\,\mathrm{d}V}_{\text{degraded elastic energy}} + \underbrace{\frac{G_c}{c_w} \int_\Omega \left( \frac{w(d)}{\ell} + \ell\,|\nabla d|^2 \right) \mathrm{d}V}_{\text{surface (fracture) energy}}.\]Three blocks worth chewing on:
-
g(d) ψ(ε)is the elastic strain energy, degraded where there is damage.ψis the usual quadratic strain energy density from linear elasticity.g(d) = (1 - d)²is the standard choice; it has the rightg(0) = 1,g(1) = 0, andg'(1) = 0to avoid stress concentration at fully-damaged points. -
w(d)/ℓis the dissipation density per unit damage. The choicew(d) = dgives the AT1 model (compact support, an actual elastic region before damage onset).w(d) = d²gives AT2 (smooth, exponential profile, no elastic limit — damage initiates the moment load is applied).c_wis a normalising constant chosen so the total surface energy of a fully-formed crack equalsG_c × (crack length). -
ℓ |∇d|²is the gradient term that makes the regularisation work. Without it,dwould degenerate to a delta function. With it, the optimal damage profile around a crack is a smooth band of width proportional to ℓ.
The two analytical profiles fall out of a 1D Euler-Lagrange calculation:
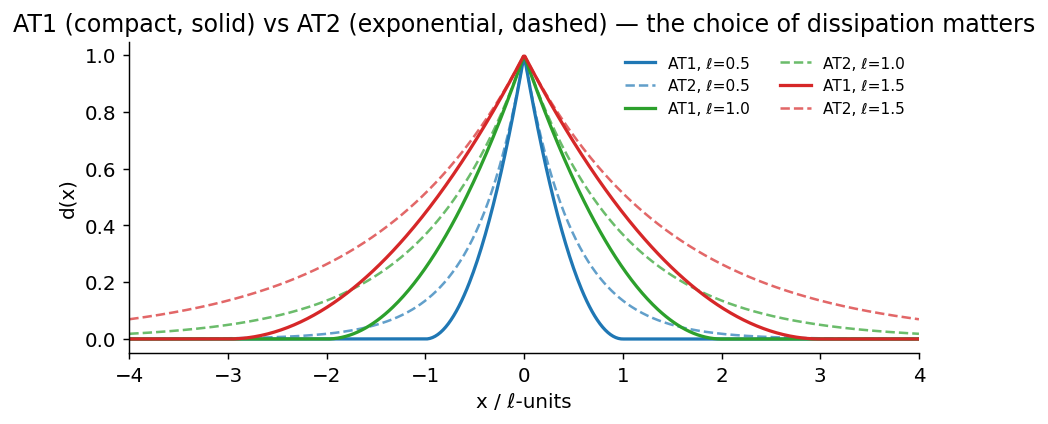
d*(x) = (1 - |x|/2ℓ)² for |x| < 2ℓ, zero outside. AT2: d*(x) = exp(-|x|/ℓ). Note the AT1 profile is compactly supported; outside the damaged band the material is truly intact. AT2 leaks damage everywhere.Drag the slider below to feel how ℓ controls width:
3. The discrete problem
The continuous energy is unhelpful for a computer. We discretise:
- Mesh the domain. Use linear triangles or bilinear quads; nothing fancier helps for phase-field.
ulives on the nodes as a vector field (dim × n_nodes degrees of freedom).dlives on the nodes as a scalar field (n_nodes DOFs).- The energy becomes a function of two big vectors:
E(U, D).
The variational principle says the solution (U, D) is a joint
minimiser of E. We almost never minimise jointly — the problem is
non-convex in (U, D) together but separately convex in each. So
practitioners use alternating minimisation:
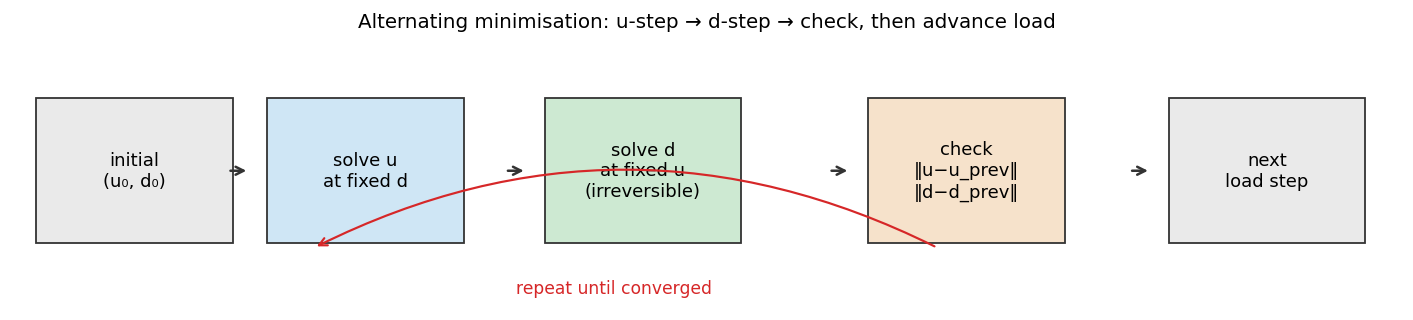
(u, d) has converged for the current load. Then advance load and start over.The two key constraints on the d-step:
- Box constraint:
d ∈ [0, 1]pointwise. - Irreversibility:
d(t + Δt) ≥ d(t)pointwise. Damage cannot heal.
The second one matters enormously. The first time you skip it because “it’s just a small Δt” your solver will silently produce thermodynamic nonsense.
4. The 80-line PyTorch sketch
The shortest convincing phase-field solver you can write in PyTorch is something like the following. This is a 1D bar in tension — the dumbest possible PF example, but everything you’d add for 2D/3D is just more indexing.
import torch
# Mesh, parameters
N, L = 121, 1.0
xs = torch.linspace(0, L, N)
dx = float(xs[1] - xs[0])
E0, Gc, ell, cw = 100.0, 1.0, 0.04, 8/3 # AT1 normaliser
# State (trainable wrt energy)
u = torch.zeros(N, requires_grad=True)
d = torch.zeros(N, requires_grad=True)
def energy(u, d, u_app):
# Element strain (constant per cell)
eps = (u[1:] - u[:-1]) / dx
d_e = 0.5 * (d[:-1] + d[1:]) # element damage
g = (1.0 - d_e) ** 2 # degradation
psi = 0.5 * E0 * eps ** 2 # elastic density
elastic = (g * psi * dx).sum()
grad_d = (d[1:] - d[:-1]) / dx
surface = (Gc / cw) * ((d_e / ell + ell * grad_d ** 2) * dx).sum()
# Dirichlet BC penalty (illustrative; in a real solver these
# are enforced by removing rows/cols from the linear system)
bc = 1e4 * (u[0] ** 2 + (u[-1] - u_app) ** 2)
return elastic + surface + bc
# Alternating-minimisation outer loop
d_prev = d.detach().clone()
for u_app in torch.linspace(0, 0.04, 50):
for k in range(40): # u-step (fixed d)
if u.grad is not None: u.grad.zero_()
E = energy(u, d.detach(), u_app)
E.backward()
with torch.no_grad(): u -= 1e-4 * u.grad
for k in range(40): # d-step (fixed u, irreversibility)
if d.grad is not None: d.grad.zero_()
E = energy(u.detach(), d, u_app)
E.backward()
with torch.no_grad():
d_new = torch.clamp(d - 0.05 * d.grad, 0.0, 1.0)
d_new = torch.maximum(d_new, d_prev) # irreversibility
d.copy_(d_new)
d_prev = d.detach().clone()
That’s it. Two coupled minimisations, an irreversibility projection, a load loop. Real production solvers — Akantu’s phase-field module, PhaFiDyn, Bourdin’s original FreeFEM++ codes, PRACE-scale MPI codes — are doing exactly this with better linear solvers, smarter convergence criteria, and adaptive meshing. The math is unchanged.
The toy version above produces this:
5. What’s hard about putting this in PyTorch
This is where most people get hurt. A short, opinionated list.
Higher-order derivatives matter. The d-step gradient passes through
(1 - d)² ψ(u), and the u-step gradient passes through
(1 - d)² ψ(u) again. Both are smooth. But if you ever introduce a
spectral split (Miehe et al., 2010) to prevent crack-closure in
compression, you have max(0, ε⁺) · max(0, ε⁻) terms whose derivatives
are well-defined almost everywhere but pathological at the eigenvalue
crossings. Naïve autograd produces gradients that look fine numerically
but make Newton iterations stall. This is the single biggest pitfall.
Irreversibility breaks the variational structure. The constraint
d(t+Δt) ≥ d(t) is a hard inequality, not part of the energy. You
enforce it either via projection (what the 80-line sketch above does)
or via a history variable (Miehe, 2010, which converts the inequality
into an extra term in the energy). The projection approach is simpler
but biases the gradient — the cells where the projection is active
have zero descent direction for further damage growth, so your line
search sees a kink. Production codes use projected-gradient or
active-set methods.
Operator-split instability under explicit dynamics. For dynamic
fracture you advance (u, d) via a Verlet-style explicit scheme. The
CFL condition is not just the elastic CFL — it tightens dramatically
as damage approaches 1. If you ignore this (because your elastic CFL
felt safe) your damage field gets gradient blow-up of order 10^96 and
the solver eats memory until OOM. Ask me how I know.
requires_grad semantics inside a load loop. PyTorch’s tape grows
unboundedly if you keep reusing the same Parameters without detaching
between load steps. For a 10⁵-node mesh and 10³ load steps, you’ll
exhaust GPU memory before you reach crack initiation. The fix is to
.detach() between load steps and reattach inside each minimisation,
which obviously breaks differentiability across load steps — which is
exactly the thing you wanted for the inverse-problem story below.
Resolving that tension is the subject of a whole sub-literature
(Akhare et al., 2025 is the
state-of-the-art for stable implicit fixed-point regimes).
6. What differentiability buys you
The PyTorch sketch in §4 has a property the legacy solvers don’t: every output is a differentiable function of every input. That includes the irreversibility projection, the load loop, and the alternating min — autograd will carry the gradient back through all of it, as long as you avoid the four pitfalls in §5.
That single property is the door. Once it’s open, the material
parameters in the equation (G_c, E, ℓ) stop being constants and
become trainable. Pick any experimental measurement of a real
cracking specimen — a load-displacement curve from an Instron, a
digital-image-correlation displacement field, a crack trajectory from a
high-speed camera — and you can recover the material parameters that
would have produced that measurement:
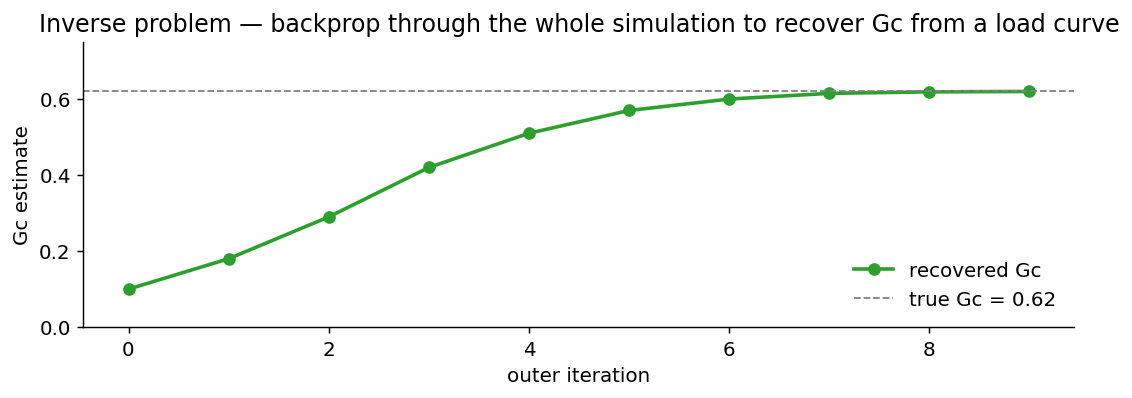
G_c recovered by backpropagating a load-curve mismatch through a phase-field simulation. The forward simulation is differentiable; the gradient comes back through every alternating-min iteration and tells the outer optimiser which direction to nudge G_c.The same simulation read two ways: a fracture mechanician calls it a forward solver (geometry + material → load curve); an applied-ML researcher calls it an inverse problem (load curve → material). Differentiability is what lets one piece of code be both.
The same property unlocks three other things people are actually shipping today:
- Gradient-based topology optimisation of toughened structures — design a part to maximise fracture resistance, not just stiffness.
- Hybrid neural acceleration — train a small network to predict the next damage increment, with the physics solver as a verifier (rejection sampling on residual norm).
- Differentiable digital twins — assimilate live sensor data into a phase-field simulation by gradient descent on initial conditions.
None of these are speculative. People are shipping all three.
7. What’s actually hard (and where the field is going)
A short editorial.
-
Benchmarks. PINN / neural-operator literature has Burgers’, Navier-Stokes, Darcy. Fracture has no canonical benchmark suite of the same rigor. The closest things are the Borden 2012 dynamic branching cases and the Kalthoff impact test, both of which require significant interpretation to compare against. Building a GPQA-equivalent for fracture is genuinely open.
-
Neural operators on PF data. Once you have a differentiable solver, generating large datasets is cheap. The hard part is the representation: damage fields are sparse and localised, which kills the spectral inductive bias of an FNO. Equivariant operators or graph-based architectures look more promising. See Mishra’s CIRM neural-operator lecture series for the theory.
-
Implicit-step differentiability. The state of the art for differentiable implicit PDE solvers is implicit-function-theorem adjoints (Akhare 2025, Im-PiNDiff). For explicit time-stepping with damage coupling — the dominant regime in dynamic fracture — gradient stability is still an open problem, and is the main thrust of my own thesis work.
-
Hybrid causation vs correlation. Neural surrogates that learn the next-step damage map are seductive but trivially overfit to a single load history. Until benchmarks include held-out out-of- distribution loadings, the literature will continue to claim 100× speedups that don’t generalise.
8. Where to go from here
If you want to build one of these yourself:
- Read the canon. Bourdin, Francfort & Marigo (2000), “Numerical experiments in revisited brittle fracture”, J. Mech. Phys. Solids 48(4). Miehe, Welschinger & Hofacker (2010), Int. J. Numer. Meth. Engng 83(10). These are the two papers that make every subsequent paper intelligible.
- Reference codes. Bourdin’s FreeFEM++ phase-field repo is the canonical implementation; Akantu has a maintained C++ phase-field module; PhaFiDyn is a validated explicit-dynamics FEniCS code worth reading end-to-end.
- My own work —
torch_pf_solveris a GPU-native, matrix-free phase-field solver in pure PyTorch with full adjoint + autograd + checkpoint differentiability. Currently private (it’s tied to in-flight thesis chapters); I’m carving out a public adjoint-demo slice — the inverse-problem cartoon above will be a runnable notebook in that repo.
If you want to use one without building it: pick Akantu (C++, fast, limited Python interface), or write a thin wrapper around the 80-line sketch above and add your physics there. The barrier to entry is much lower than the literature suggests.
If you read this far and have feedback or want to discuss differentiable solvers more generally, my email is in the site footer. I am especially interested in hearing about benchmark cases that should exist but don’t.
References
- Griffith, A. A. (1921). The phenomena of rupture and flow in solids. Philosophical Transactions of the Royal Society A 221(582–593), 163–198. doi:10.1098/rsta.1921.0006
- Francfort, G. A., & Marigo, J.-J. (1998). Revisiting brittle fracture as an energy minimization problem. Journal of the Mechanics and Physics of Solids 46(8), 1319–1342. doi:10.1016/S0022-5096(98)00034-9
- Bourdin, B., Francfort, G. A., & Marigo, J.-J. (2000). Numerical experiments in revisited brittle fracture. Journal of the Mechanics and Physics of Solids 48(4), 797–826. doi:10.1016/S0022-5096(99)00028-9 — the original phase-field-for-fracture paper.
- Ambrosio, L., & Tortorelli, V. M. (1990). Approximation of functionals depending on jumps by elliptic functionals via Γ-convergence. Communications on Pure and Applied Mathematics 43(8), 999–1036. doi:10.1002/cpa.3160430805 — the Γ-convergence guarantee that makes the whole field rigorous.
- Miehe, C., Welschinger, F., & Hofacker, M. (2010). Thermodynamically consistent phase-field models of fracture: Variational principles and multi-field FE implementations. International Journal for Numerical Methods in Engineering 83(10), 1273–1311. doi:10.1002/nme.2861 — the staggered scheme + history-variable formulation cited in §5.
- Borden, M. J., Verhoosel, C. V., Scott, M. A., Hughes, T. J. R., & Landis, C. M. (2012). A phase-field description of dynamic brittle fracture. Computer Methods in Applied Mechanics and Engineering 217–220, 77–95. doi:10.1016/j.cma.2012.01.008 — the dynamic-branching benchmark cases.
- Pham, K., Amor, H., Marigo, J.-J., & Maurini, C. (2011). Gradient damage models and their use to approximate brittle fracture. International Journal of Damage Mechanics 20(4), 618–652. doi:10.1177/1056789510386852 — the AT1 vs AT2 distinction.
- Akhare, D., Luo, T., & Wang, J.-X. (2025). Im-PiNDiff: Implicit physics-informed neural differentiable solver for stiff temporal systems. arXiv:2504.02260 — the implicit-step differentiability state-of-the-art cited in §7.
- Lu, L., Jin, P., Pang, G., Zhang, Z., & Karniadakis, G. E. (2021). Learning nonlinear operators via DeepONet. Nature Machine Intelligence 3, 218–229. arXiv:1910.03193
- Li, Z., Kovachki, N., Azizzadenesheli, K., et al. (2021). Fourier neural operator for parametric partial differential equations. ICLR 2021. arXiv:2010.08895
- Mishra, S. (2024). Learning operators — Lecture 1, CIRM Marseille. YouTube
- Rush, A. M. (2018). The Annotated Transformer. Harvard NLP. nlp.seas.harvard.edu — the explainer format borrowed for this post.
Related: PINNs tutorial — the data-vs-physics warm-up that this post extends. Cross-posted from the Tutorials series.
]]>